

Easy methods to Create Instagram Reels With out Being On Digital camera: A Step-by-Step Information
Are you tired of the hassle of getting camera-ready for every Reel you post? Well, today’s your lucky day because we’re diving into the world of creating Instagram Reels without getting on camera, using the voiceover feature!
Wish you could post a Reel without spending all the time and energy it takes to get mentally and physically “camera-ready”? Using the voiceover feature can help you create relevant and valuable posts in a pinch.
Let’s dive into an example of posts we’ve done that are using the voiceover.
Click above to watch this reel.
Notice how we’re using a collection of videos where we’re not talking directly to the camera. This feature can be used by both product and service-based businesses.
Ideas This Will Work For Your Business
Now, let’s explore some ideas that may work for your business with voiceover: You could use it to explain a process, show a day in the life, share your experience, give motivation, explain a misconception about your industry, or provide a business update.
The opportunities are endless! And remember, you can “build a bridge” between what is being shown in the video and what is being said in the voiceover.
So how do you go about creating something like this? We are going to walk you through it!
Step By Step Voiceover Walk Thru
Select a video on your camera that can represent or relate to your business in some way. Consider the intention of your business. What value are you providing to the future viewer? The Intention can be entertainment, inspiration, or education.
Once you decide on the video footage you’re going to use, you can go ahead and click the plus icon on your screen and tap Reel.
Click your photo library on the bottom left of your screen to select the video or video clips that you’ve decided on.
This is where you can trim any of the clips if needed. You can make these kinds of reels short and sweet, or longer depending on your intention.
After trimming (if needed) and clicking Next, select “Edit video” in the bottom left of your screen.

This opens up the video edit screen where you can once again trim your video, add audio, control the volume – and much more. Instagram keeps adding features to Reel editing so definitely look around.
Scroll to the right of the icons at the bottom of the screen until you see Voiceover. Tap it, and use the white button to record your voiceover. It will count down from 3 for you. Make sure you are starting at the beginning of your video (or wherever you want your voice to come in.) Notice how long your video is and make sure you can say everything you plan to say within that time.
You can play back your recording and redo it if needed. Just click the play button to hear how it sounds, and discard it if you want to start over. Make sure if starting the recording over you move the white bar to the beginning of the video to indicate where you want your recording to start playing.
Another PRO tip is to select Volume from the bottom icon screen (right next to the Voiceover icon). This controls the different sounds on your Reel. You can have multiple sounds playing at once, or you can turn your camera audio down so the voiceover is easily heard.
Once you’re happy with your recorded voiceover click Done, and you’ll need to determine your hook and use the text tool to add it. The hook is the first bit of text the audience will see and determines if they’ll want to stick around and watch the video, so it’s super important to include!

Text Tool(arrow)
And if your voiceover is different or includes more than the hook, don’t forget to add captions! A lot of Instagram users watch reels on silent, so you need captions to make sure they stick around for your entire video.

Sticker icon to find captions
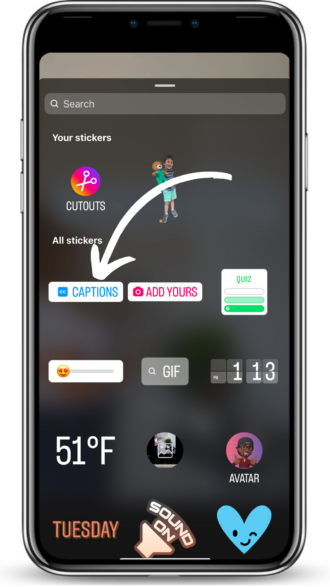
Auto captions
Next up is your typical Reel requirements – edit the cover photo – select profile grid where you can decide how your video and hook look in your grid. Then tag people or locations, add a description, and you’re ready to post!
Next Steps
As we said before, the possibilities for this Reel idea are endless. It requires a bit of creativity and practice, but we believe that this is a great option for mixing up your content. It also gives you a different option than always being on camera, speaking to the camera.
And if you’re ready for some easy hacks for your videos on Instagram, be sure to download our free guide “5 Quick and Easy Hacks For More Professional and Engaging Reels.” It’s free and available to download just by clicking this link.

Comments are closed.