

What the research is:
Silent data corruption or data errors that are not recognized by the larger system are a common problem for large infrastructure systems. This type of corruption can spread across the stack and manifest itself as application-level problems. This can also result in data loss and take months to debug and resolve. This thesis describes best practices for detecting and correcting silent data corruption on a scale of hundreds of thousands of computers.
In our article, we examine common types of errors observed in CPUs using a real-world example of silent data corruption in a data center application resulting in missing rows in the database. We’ll map a high level debug flow to determine the root cause and identify the missing data.
We find that reducing silent data corruption requires not only hardware resilience and production detection mechanisms, but also robust, fault-tolerant software architectures.
How it works:
Silent errors can occur during any set of functions within a data center CPU. We describe an example in detail to illustrate the debug methodology and our approach to addressing this in our large fleet. In a large infrastructure, files are typically compressed when they are not being read and decompressed when a request is made to read the file. Millions of these operations are performed every day. In this example we will mainly focus on the decompression aspect.
Before decompression, the file size is checked to see if the file size is> 0. A valid compressed file of content would have a non-zero size. In our example, when calculating the file size, a file with a non-zero file size was provided as input for the decompression algorithm. Interestingly, the calculation returned a value of 0 for a non-zero file size. Because the result of the file size calculation was returned as 0, the file was not written to the decompressed output database.
In some random scenarios, the decompression activity was skipped when the file size was not zero. As a result, the database, which relied on the actual contents of the file, was missing files. These files with empty content and / or incorrect size are passed on to the application. An application that maintains a list of key-value memory mappings for compressed files immediately detects that some compressed files are no longer recoverable. This chain of dependencies causes the application to fail, and the querying infrastructure eventually reports data loss after decompression. It adds complexity because it occasionally happens when engineers plan the same workload on a cluster of machines.
Recognizing and reproducing this scenario in a large environment is very complex. In this case, the reproducer was reduced to a single machine workload at the infrastructure level for querying multiple machines. Based on the individual machine utilization, we found that the errors were really sporadic in nature. The workload was identified as multithreaded, and when threading the workload once, the error was no longer sporadic but consistent for a specific subset of data values on a specific core of the machine. The sporadic nature associated with multithreading was eliminated, but the sporadic nature associated with the data values remained. After a few iterations it became clear that the computation of
Int (1.153) = 0
as input for the math.pow function in Scala always generates a result of 0 on Core 59 of the CPU, but if the calculation is changed to
Int (1.152) = 142
The result is accurate.
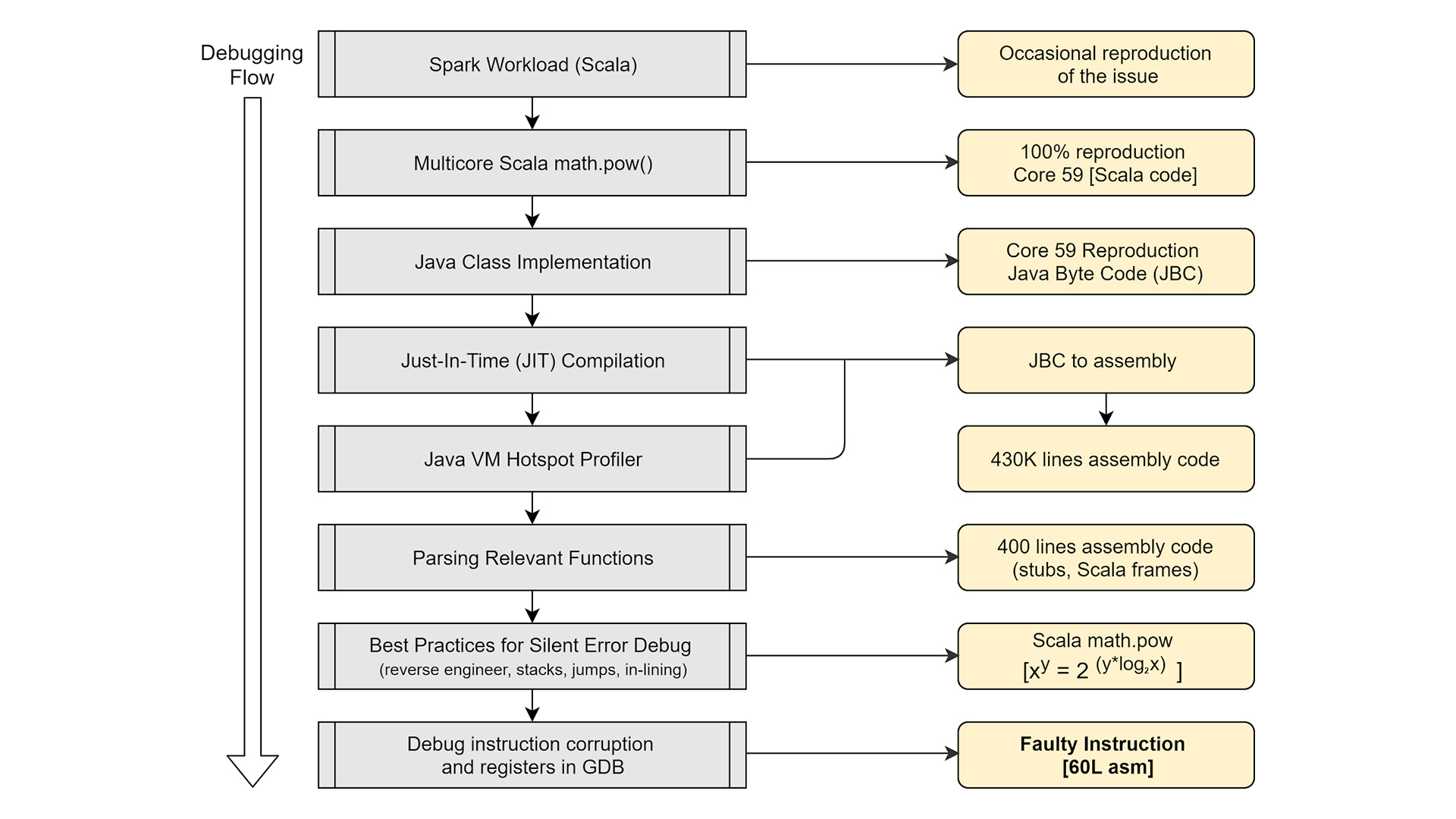
The diagram above documents the cause flow. The corruption affects calculations, which can also be non-zero. For example, the following incorrect calculations were made on the machine identified as defective. We found that the calculation affects the positive and negative powers for certain data values. In some cases the result was non-zero when it should be zero. Incorrect values were obtained with varying degrees of accuracy.
Example error:
Int [(1.1)3] = 0, expected = 1
Int [(1.1)107] = 32809, expected = 26854
Int [(1.1)-3] = 1, expected = 0
For an application, this leads to decompressed files that are incorrectly sized and incorrectly truncated without an EoF terminator (end-of-file). This leads to dangling file nodes, missing data and no traceability of damage within an application. The intrinsic data dependency on the kernel as well as on the data inputs makes it difficult to computationally identify these types of problems without a specific playback device and to determine the root cause. This is especially difficult when hundreds of thousands of machines are doing several million calculations per second.
After integrating the reproducer script into our detection mechanisms, additional machines were flagged as faulty for the reproducer. As a result of these investigations, several software and hardware resilient mechanisms were integrated.
Why it matters:
Silent data corruption is observed more and more frequently in data centers than before. In our article, we present an example that illustrates one of the many scenarios that can arise when dealing with data-dependent, withdrawn, and hard-to-debug errors. Multiple detection and mitigation strategies add complexity to the infrastructure. A better understanding of this damage helps us to increase the fault tolerance and resilience of our software architecture. Together, these strategies help us make the next generation of infrastructure computing more reliable.
Read the full paper:
Silent data corruption on a scale
Comments are closed.