

Jeden Arbeitstag verpflichten Facebook-Ingenieure Tausende von Unterschieden (was eine Änderung ist, die aus einer oder mehreren Dateien besteht) in die Produktion. Diese Codegeschwindigkeit ermöglicht es uns, schnell neue Funktionen zu liefern, Fehlerbehebungen und Optimierungen bereitzustellen und Experimente durchzuführen. Ein natürlicher Nachteil einer schnellen Bewegung in einer Branche ist jedoch das Risiko, dass die Leistung, Zuverlässigkeit oder Funktionskorrektheit versehentlich beeinträchtigt werden.
Um unsere Entwicklerinfrastruktur auf dieses Volumen zu skalieren und gleichzeitig Regressionen zu verringern und zu minimieren, erstellen wir Tools und Mechanismen, mit denen Ingenieure verstehen können, ob ein Diff eine Regression eingeführt hat (oder wird). Wir betrachten das Feedback, das wir von diesen Tools erhalten, als Signale. Signale kann durch automatisierte Tests, statische Analyse-Frameworks, Leistungsprotokolle, Crash-Dumps, Fehlerberichte, Produktionsüberwachungsalarme und Dutzende anderer Quellen generiert werden. Diese Signale können in jeder Phase des Entwicklungslebenszyklus auftauchen. Ein bestimmtes Diff kann Hunderte von Signalen erzeugen – einschließlich Fehlern, Erfolgen und Warnungen -, die einem Ingenieur helfen können, zu beurteilen, ob dieses Diff bereit ist, in einem stabilen Zweig gelandet zu werden, und seinen Weg in die Produktion zu finden. Nachdem ein Diff gelandet ist, wird das Signal normalerweise über unser Task-Management-System an die Ingenieure gesendet. Ein einzelner Ingenieur kann leicht Hunderte von Aufgaben in seinem Rückstand haben.
Da für jeden Ingenieur ständig so viel Signal generiert wird, kann es für einen Ingenieur schnell überwältigend werden, zu wissen, wo er seine Zeit konzentrieren muss. Ein sehr wichtiges Signal könnte übersehen werden, da es von verrauschten Signalen mit niedrigerer Priorität übertönt wird. Dies erschwert es den Ingenieuren, die relative Priorität für jedes Signal schnell oder einfach zu bestimmen. Möglicherweise verbringen sie Stunden damit, ein Problem zu debuggen, das sich als Rauschen herausstellte, oder es fehlen ihnen die erforderlichen Informationen, um es zu diagnostizieren und zu beheben.
Im Laufe der Zeit, als wir mehr Werkzeuge und Überwachungssysteme bauten, nahm die Signallautstärke zu, bis sie zu einer anhaltenden Ablenkung wurde. Schließlich stellten wir fest, dass wir eine effektivere Methode benötigen, damit Ingenieure leicht erkennen können, woran sie zuerst arbeiten müssen, und weniger Zeit für das Debuggen und Beheben von Problemen aufwenden müssen.
Effizientere Korrekturen
Wir haben gesehen, dass die Behebung von Fehlern im Laufe des Entwicklungsprozesses exponentiell zeitaufwändiger wird. Dies gilt für die meisten Fertigungsindustrien, unabhängig davon, ob Sie Autos herstellen, Wolkenkratzer bauen oder Software versenden. Wir sehen dies deutlich in unseren eigenen Daten:
- Ein in der integrierten Entwicklungsumgebung (IDE) festgestellter Fehler, während ein Techniker codiert, kann in wenigen Minuten behoben werden.
- Ein Fehler, der während der Überprüfung eines Differentials festgestellt wurde, kann in Stunden behoben werden.
- Wenn derselbe Defekt landen und in die Produktion gelangen darf, kann es Tage dauern, bis ein Fehler behoben ist.
Die durchschnittliche Zeit, die zur Behebung von Problemen benötigt wird, steigt exponentiell an, je weiter sich ein Defekt in der Entwicklungsphase befindet.
Jede Lösung zur Verkürzung der Fixzeiten müsste sicherstellen, dass Regressionen erkannt und behoben werden so früh wie möglich im Prozess.
Einführung von Fix Fast
Um diesen Herausforderungen zu begegnen, haben wir 2019 unsere funktionsübergreifende Aktion Fix Fast gestartet. Fix Fast bringt die Entwicklungsteams zusammen, die für die Erzeugung des Löwenanteils der Signale verantwortlich sind, die Regressionen in Bezug auf Leistung, Zuverlässigkeit und Funktionskorrektheit darstellen. Die Mission dieser Bemühungen bestand darin, den Aufwand zu verringern, der erforderlich ist, um Regressionen im Maßstab zu beheben, indem die technische Erfahrung verbessert und die umsetzbare Erkennung weiter nach oben verschoben wird.
Obwohl die Strategie auf hoher Ebene klar war, hatten wir noch einige große Fragen zu beantworten: Mit welchen Problemen sollten wir beginnen? Wie sollen wir den Fortschritt messen? Wir wussten, dass wir einen datengesteuerten Ansatz benötigen würden, um dieses Ziel auf Facebook-Ebene zu erreichen. Deshalb haben wir zunächst einen Weg gefunden, um den Aufwand zu messen und Benchmarks zu setzen.
Eine Metrik für schnellere Korrekturen
Bei der Verfolgung einer Metrik haben wir viele Optionen in Betracht gezogen. Letztendlich sind wir auf eine Metrik gestoßen, die Ingenieure dazu anregen würde, nach links zu wechseln, eine branchenübliche Praxis, Regressionen so früh wie möglich im Entwicklungslebenszyklus zu erkennen (und zu beheben). Wie oben erwähnt, ist es wesentlich weniger zeitaufwändig, einem Techniker zu helfen, ein Problem in der IDE zu erkennen und zu beheben, während er sich noch auf diesen Codeblock konzentriert, als dasselbe Problem zu erkennen, sobald der Code in Produktion ist.
Wir haben eine einheitliche Metrik der obersten Ebene entwickelt, die als Cost-per-Developer (CPD) bezeichnet wird, sodass frühere Phasen eines Fixes weniger gewichtete Kosten erhielten als spätere Phasen. (Beachten Sie, dass der Begriff „Kosten“ verwendet wird, um die Zeit darzustellen, die ein Ingenieur für die Behebung eines Problems benötigt, im Gegensatz zu einem direkten Dollarbetrag.) Die Gewichte für jede Stufe wurden ermittelt, indem interne Daten analysiert und strenge Backtests durchgeführt wurden, um den relativen Wert zu bestimmen Die Ingenieure verbrachten bereits Zeit damit, Regressionen in jeder Phase zu korrigieren. Dieser Ansatz förderte die Erkennung und Prävention von Problemen in früheren Phasen des Lebenszyklus. Es war auch ein Anreiz für Ingenieure, sich auf Rauschunterdrückung, Signalwirkbarkeit und andere Verbesserungen innerhalb der Stufe zu konzentrieren. Auf diese Weise wird sichergestellt, dass nicht nur Signale erkannt werden, sondern dass die zuständigen Ingenieure die Probleme schnell beheben können, bevor der Code in die nächste Phase des Entwicklungslebenszyklus übergeht.
Durch die Bewertung der Fortschritte bei der CPD konnte das Team einen quantitativen Ansatz zur Verfolgung von Projekten in jeder Phase verfolgen, um die Engineering-Zeit für die Behebung von Regressionen zu reduzieren.
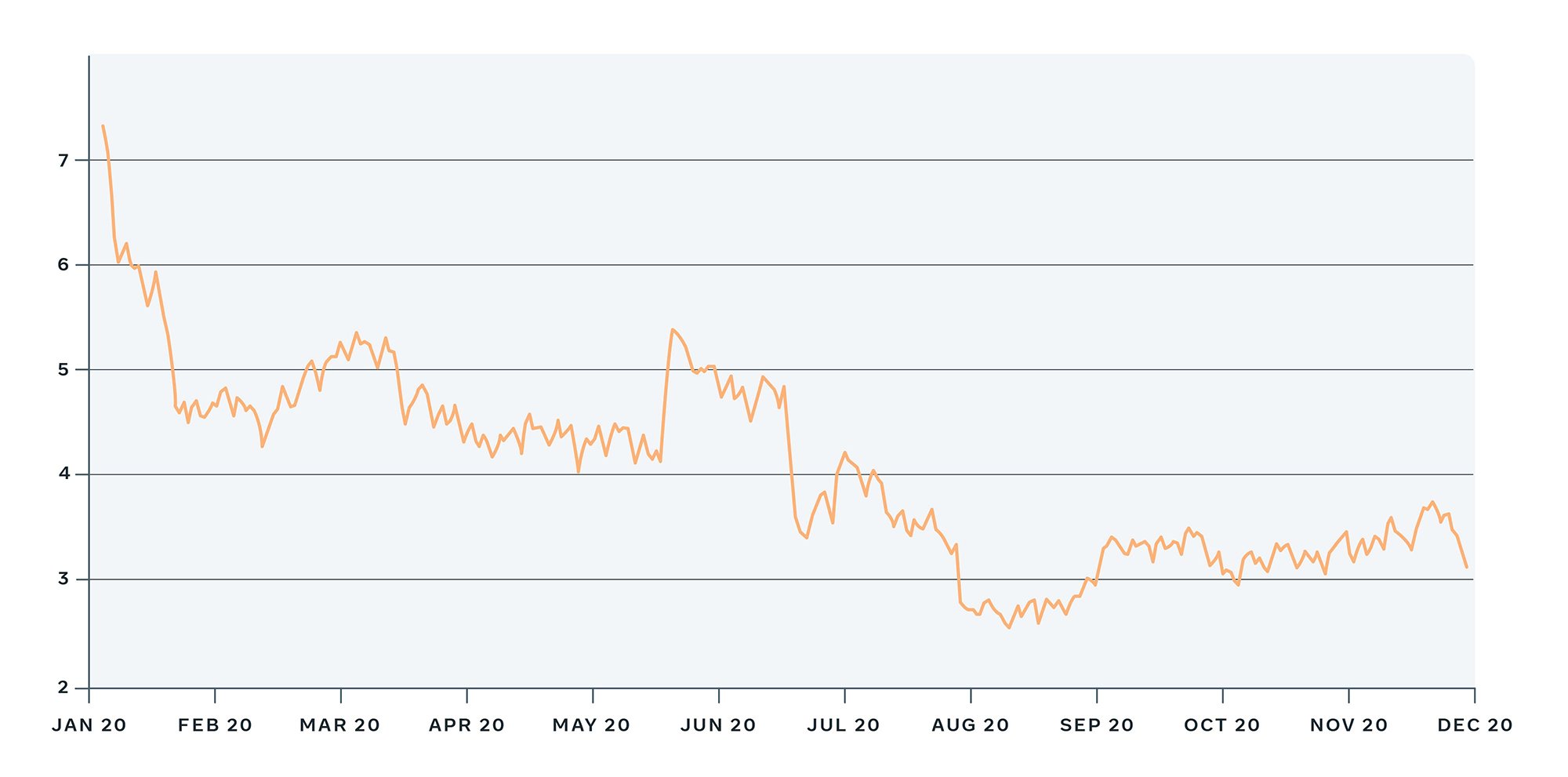 Die Kosten pro Entwickler (Cost-per-Developer, CPD) gingen im Laufe des Jahres 2020 zurück, als Verbesserungen im Zusammenhang mit Fix Fast implementiert wurden.
Die Kosten pro Entwickler (Cost-per-Developer, CPD) gingen im Laufe des Jahres 2020 zurück, als Verbesserungen im Zusammenhang mit Fix Fast implementiert wurden.
Projektspielbuch
Sobald die CPD eingerichtet war, entwickelte das Fix Fast-Team ein Playbook mit Ansätzen, die nachweislich Verbesserungen in Bezug auf Linksverschiebung, Geräuschreduzierung, Umsetzbarkeit und mehr erzielt hatten.
Nach links verschieben
Eine frühere Erkennung ist bei weitem die erste Möglichkeit, um die Fixzeiten zu verkürzen. Automatisierte Tests sind wichtig, um sicherzustellen, dass Regressionen nicht in die Produktion befördert werden. Das Ausführen von Tests in Continuous Integration (CI) und Produktion erfordert jedoch eine erhebliche Menge an Kapazität und Zeit für Rechenzentren. Angesichts der schieren Anzahl von Unterschieden, die jeden Tag getestet werden müssen, und der Anzahl der Tests, aus denen wir auswählen können, haben wir sie eingesetzt komplexe Heuristiken und Algorithmen für maschinelles Lernen um bei der Auswahl der besten Tests für jede Phase unter Berücksichtigung der verfügbaren Zeit und Kapazität zu helfen. An einem typischen Tag führt Facebook allein bei Diffs Millionen von Tests durch.
Wir entwickeln auch automatisierte Tests innerhalb der IDE, damit Ingenieure eine Teilmenge von Tests ausführen können, während sie codieren, bevor sie ihren Code überhaupt zur Überprüfung einreichen. IDE-Testergebnisse werden in Minuten zurückgegeben. Mit diesem Ansatz können Ingenieure jetzt 90 Prozent früher Testsignale empfangen, und wir haben die Anzahl der Fehler nach dem Festschreiben um mehr als 10 Prozent verringert.
Signalqualität
Das Reduzieren von verrauschten, doppelten oder nicht umsetzbaren Signalen ist wichtig, um sicherzustellen, dass Ingenieure wissen, welche Signale wichtig sind, und dass sie zugrunde liegende Regressionen schnell beheben können.
Um dies anzugehen, mussten wir zunächst verstehen, welche Signale zu nützlichen Ergebnissen führten. Nachdem wir Hunderte solcher Signale manuell analysiert hatten, entwickelten wir eine Heuristik, die als sinnvolle Aktion bezeichnet wurde, um Aufgaben darzustellen, die nützlich waren und zu einer Aktion eines Ingenieurs führten. Die sinnvolle Aktionsheuristik berücksichtigt menschliche Kommentare, Unterschiede, die mit einer Aufgabe verbunden sind, oder andere nicht triviale Aktionen. Durch systematisches Entfernen der ungesunden Bots (diejenigen, die eher verrauschte oder auf andere Weise inaktive Signale erzeugen) konnten wir Signale de-täuschen und sie den richtigen Regressionsmetriken mit einem angemessenen Schwellenwert für das Auslösen zuordnen. Den Aufgaben wurden genaue und umsetzbare Informationen hinzugefügt, um den Benutzern klare Anweisungen zur Problembehebung zu geben.
Ein Beispiel dafür ist GesundheitskompassHier haben wir die aussagekräftige Aktionsquote im vergangenen Jahr erfolgreich um 20 Prozent verbessert, indem wir das Rauschen reduziert und die Regressionserkennungslogik optimiert haben.
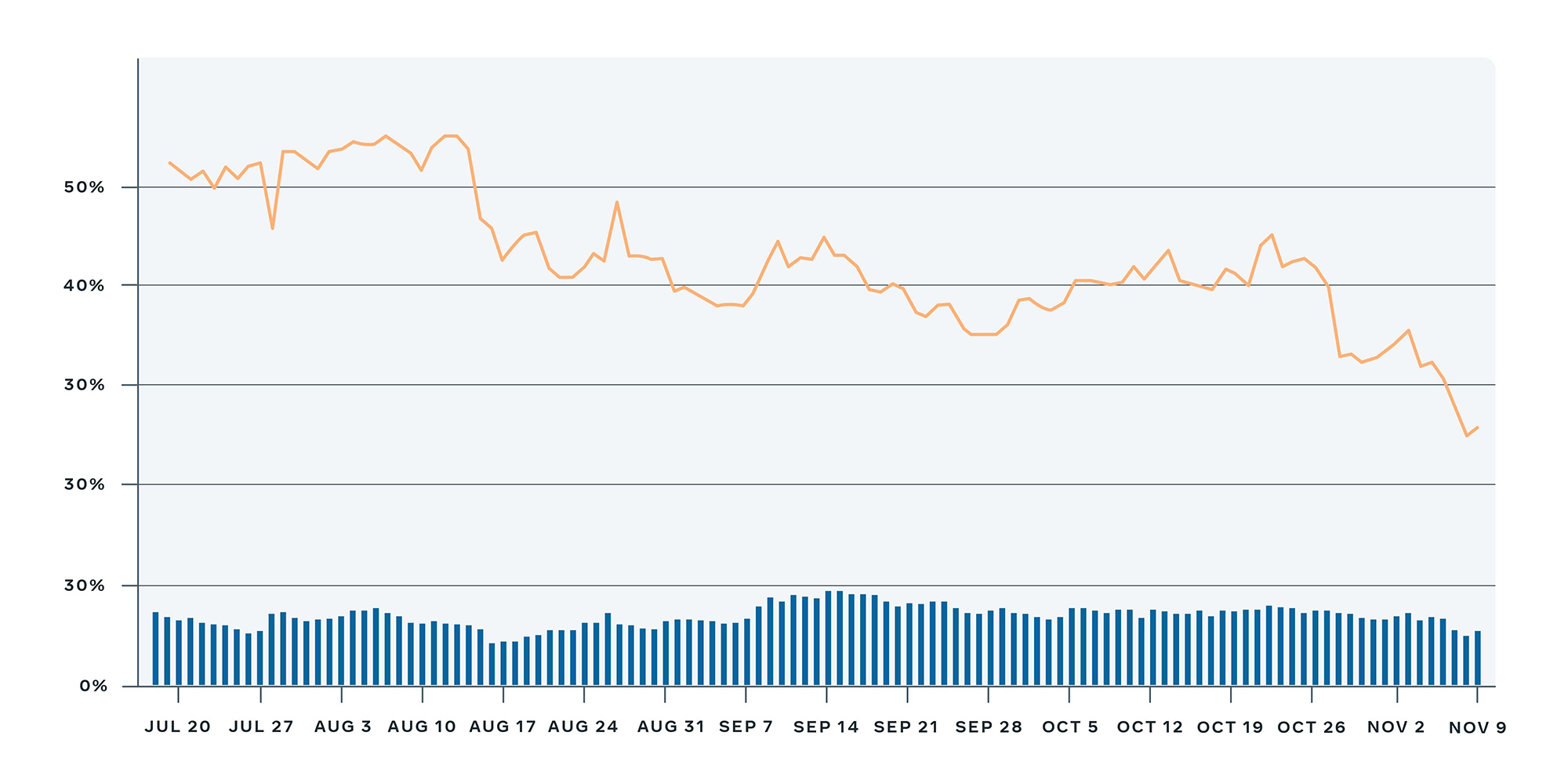 Verbesserungen der Qualität der Regressionserkennung von Health Compass, die sich in einer Reduzierung von „lauten“ Aufgaben zeigt.
Verbesserungen der Qualität der Regressionserkennung von Health Compass, die sich in einer Reduzierung von „lauten“ Aufgaben zeigt.
Schnellere Zuordnung
Wenn Sie das Signal zum ersten Mal vor die richtige Person bringen, können Sie Tage der Fixzeit sparen. Dies ist jedoch oft leichter gesagt als getan. Wenn eine Aufgabe dem falschen Eigentümer zugewiesen wird, kann sie im Unternehmen Tischtennis spielen, bevor sie schließlich mit jemandem landet, der sie reparieren kann. In internen Tests haben wir festgestellt, dass für Aufgaben, die drei oder mehr Eigentümer hatten, bevor sie gelöst wurden, fast 50 Prozent der Zykluszeit der Aufgabe für Ping-Pong-Neuzuweisungen aufgewendet wurden, bevor der richtige Eigentümer erreicht wurde.
Ein Gewinn wurde erzielt, indem der Aufgabe einfach die Schaltfläche “Ich bin nicht der richtige Besitzer” hinzugefügt wurde. Zuvor mussten die Ingenieure den nächstbesten Eigentümer selbst ausfindig machen, was zu einer erheblichen Verzögerung führen und verhindern konnte, dass sie zu einer neuen Aufgabe übergehen. Wenn ein Ingenieur angibt, dass er nicht die richtige Person ist, um ein Problem zu beheben, aktiviert der Eigentümerauswahlalgorithmus die nächstbeste Vorhersage, um die Aufgabe zuzuweisen. Diese Daten werden auch verwendet, um unseren Algorithmus zur Auswahl von Eigentumsrechten im Laufe der Zeit zu verbessern.
Eine bessere Regressions-Triage und Ursachenanalyse sind wichtig, um dieses Problem zu lösen. Eine der größten Erfolgsgeschichten in diesem Bereich ist unser Multisect-Service. Multisect analysiert einen Zweig, um die Grundursache bis zu dem spezifischen Diff zurückzuverfolgen, bei dem eine Regression eingeführt wurde. In diesem Jahr haben wir daran gearbeitet, diesen Prozess zu beschleunigen. Infolgedessen können wir das richtige Diff jetzt 3x schneller als zuvor finden.
Mach dich sauber, bleib sauber
Eine andere Strategie, die wir angewendet haben, besteht darin, ein Landblockierungssignal zu implementieren, um zu verhindern, dass Regressionen gefördert werden. Null-Zeiger-Ausnahmen (NPE) sind ein häufiger Absturztyp, der Hunderte Millionen Android-Benutzer der Facebook-App-Familie betrifft. Erstellen von Java-Klassen NullSafe ist ein wichtiger Schritt zur Reduzierung und Beseitigung dieser Abstürze.
Unsere Daten haben gezeigt, dass Nicht-NullSafe-Java-Dateien dreimal häufiger zu NPE-Abstürzen führen als JavaS-Dateien, die NullSafe sind. Je mehr NullSafe-Probleme eine Datei hat, desto wahrscheinlicher ist es, dass sie mit NPE-Abstürzen in Verbindung gebracht wird. Im Jahr 2020 haben wir statische Analysen angewendet, um Code zu erkennen, der noch nicht NullSafe ist, und um Ingenieuren Tools zur Verfügung zu stellen, mit denen diese Probleme schnell behoben werden können. Aber vielleicht am wichtigsten ist, dass eine Klasse, die keine NullSafe-Probleme mehr hat, mit einer @ NullSafe-Annotation gekennzeichnet ist. Dadurch wird verhindert, dass der Code erneut hochgestuft wird, wenn neue NullSafe-Probleme auftreten.
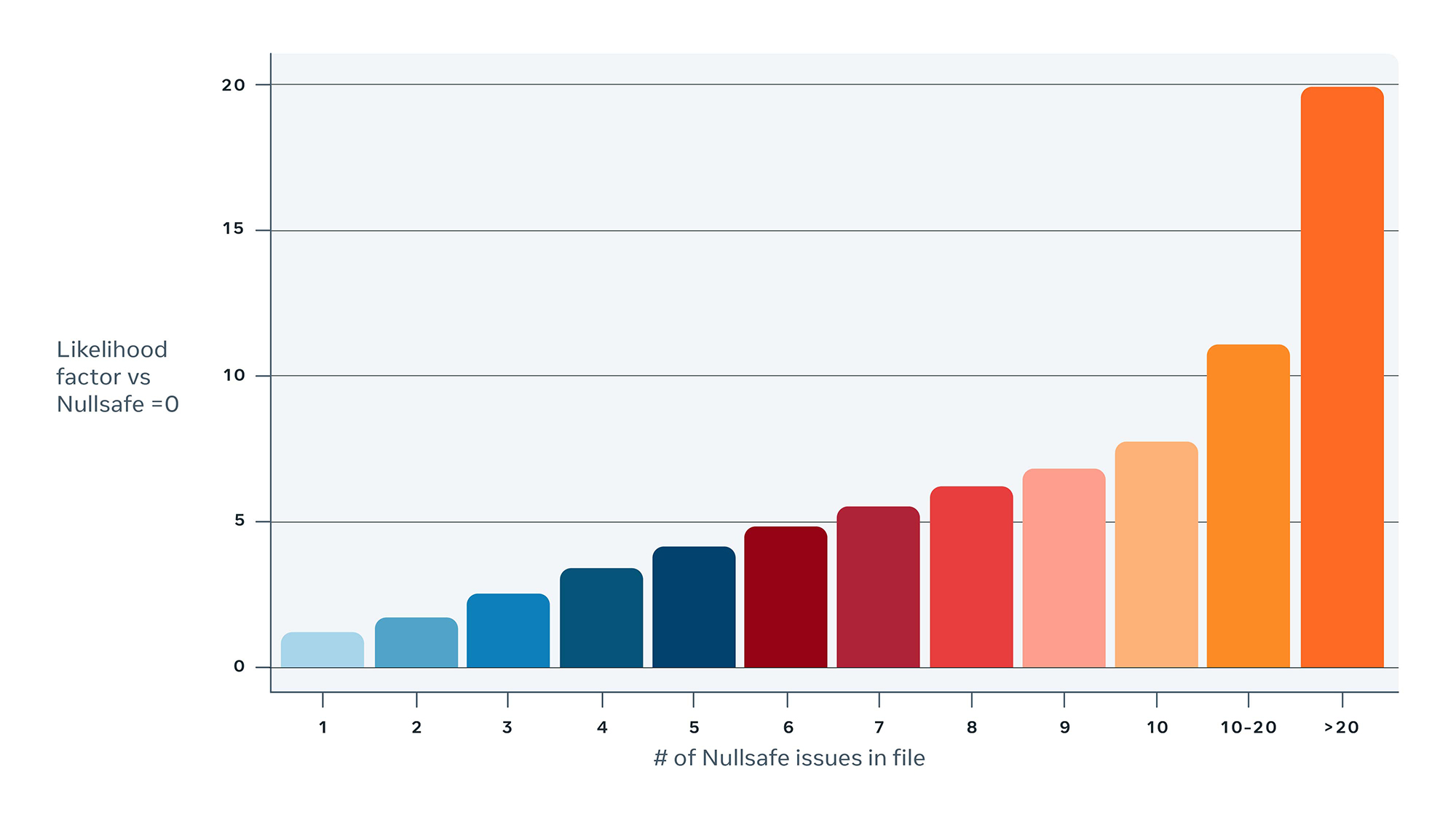 Je mehr NullSafe-Probleme in einer bestimmten Java-Datei vorhanden sind, desto höher ist die Wahrscheinlichkeit, dass diese Datei zu einem NPE-Absturz beiträgt.
Je mehr NullSafe-Probleme in einer bestimmten Java-Datei vorhanden sind, desto höher ist die Wahrscheinlichkeit, dass diese Datei zu einem NPE-Absturz beiträgt.
Was kommt als nächstes?
Durch die Implementierung all dieser Verfahren können wir einen größeren Prozentsatz von Regressionen früher im Engineering-Lebenszyklus erkennen und so den Gesamtaufwand für die Behebung dieser Regressionen reduzieren. Zusätzliche Arbeiten im Bereich des maschinellen Lernens und anderer Techniken werden ständig durchgeführt, um die beste Mischung von Früherkennungstechniken im Maßstab zu überwachen und zu verfeinern.
Wir haben auch eine Reihe robuster Metriken erstellt, mit denen sichergestellt werden kann, dass die Qualität der an Ingenieure gelieferten Regressionssignale ausreicht, um zugrunde liegende Regressionen schnell zu ermitteln, zu diagnostizieren und zu reparieren, ohne sie mit potenziell verrauschten oder doppelten Signalen zu überfordern. In naher Zukunft werden wir in Systeme investieren, die die Empfindlichkeit von Regressionsdetektoren automatisch einstellen können, ohne dass ein Ingenieur diese Metriken proaktiv überwachen muss. Beispielsweise kann ein Detektor, der möglicherweise verrauschte oder nicht inaktive Signale erzeugt, vorübergehend deaktiviert werden, bis ein Techniker das Problem diagnostizieren kann, wodurch verhindert wird, dass unnötiges Rauschen erzeugt wird.
Letztendlich haben sich diese Techniken nicht nur für Ingenieure als vorteilhaft erwiesen, um den Zeitaufwand für die Korrektur von Regressionen zu reduzieren, sondern auch für Kunden, die von weniger Regressionen und schnelleren Korrekturen profitieren.
Comments are closed.