

Die Entwicklung eines personalisierten Ranking-Systems für mehr als 2 Milliarden Menschen (alle mit unterschiedlichen Interessen) und einer Vielzahl von Inhalten zur Auswahl stellt erhebliche, komplexe Herausforderungen. Dies ist etwas, das wir jeden Tag mit dem Newsfeed-Ranking angehen. Ohne maschinelles Lernen (ML) könnten die Newsfeeds von Personen mit Inhalten überflutet werden, die sie nicht als relevant oder interessant erachten, einschließlich übermäßig werblicher Inhalte oder Inhalte von Bekannten, die häufig posten, wodurch die Inhalte der Personen begraben werden können, denen sie am nächsten stehen . Es gibt ein Ranking, um diese Probleme zu lösen. Wie können Sie jedoch ein System erstellen, das so viele verschiedene Arten von Inhalten auf eine Weise darstellt, die für Milliarden von Menschen auf der ganzen Welt persönlich relevant ist? Wir verwenden ML, um vorherzusagen, welche Inhalte für jede Person am wichtigsten sind, um eine ansprechendere und positivere Erfahrung zu unterstützen. Modelle für sinnvolle Interaktionen und Qualitätsinhalt werden mit modernster ML betrieben, z. B. Multitasking-Lernen in neuronalen Netzen, Einbettungen und Offline-Lernsysteme. Wir teilen neue Details darüber mit, wie wir ein ML-basiertes Newsfeed-Ranking-System entwickelt haben.
Erstellen eines Ranking-Algorithmus
Um zu verstehen, wie dies funktioniert, beginnen wir mit einer hypothetischen Person, die sich bei Facebook anmeldet: Wir nennen ihn Juan. Seit Juans Login gestern hat sein guter Freund Wei ein Foto von seinem Cockerspaniel gepostet. Eine andere Freundin, Saanvi, hat ein Video von ihrem morgendlichen Lauf gepostet. Und seine Lieblingsseite veröffentlichte einen interessanten Artikel über die beste Art, die Milchstraße bei Nacht zu betrachten, während seine Lieblingskochgruppe vier neue Sauerteigrezepte veröffentlichte.
Da Juan mit den Produzenten dieses Inhalts verbunden ist oder sich dafür entschieden hat, ihm zu folgen, ist alles wahrscheinlich relevant oder interessant für ihn. Um einige dieser Dinge in Juans Newsfeed höher einzustufen als andere, müssen wir lernen, was für Juan am wichtigsten ist und welcher Inhalt für ihn den höchsten Wert hat. In mathematischen Begriffen müssen wir eine Zielfunktion für Juan definieren und eine Einzelzieloptimierung durchführen.
Nehmen Sie zum Beispiel Saanvis Laufvideo. Auf Facebook ist ein konkretes beobachtbares Signal, dass ein Artikel für jemanden von Wert ist, wenn er auf die Schaltfläche “Gefällt mir” klickt. Aufgrund verschiedener Attribute kennen wir einen Beitrag (der auf einem Foto markiert ist, wann er veröffentlicht wurde usw.), Wir können die Eigenschaften des Beitrags verwenden Schlagen in Richtung Betrachter j zum Zeitpunkt t, und vorhersagen UNDite (ob Juan die Post gefallen könnte). Mathematisch schätzen wir für jeden Beitrag i UNDite = f (xijt1; xijt2; … XijtC), wobei c ein Merkmal darstellt c (1 ..C.) wie die Art des Beitrags oder die Beziehung zwischen dem Betrachter und dem Autor des Beitrags (z. B. ob sie sich gegenseitig als Familienmitglieder markiert haben) und die Funktion f (.) kombiniert die Attribute zu einem einzigen Wert.
Wenn Juan beispielsweise dazu neigt, häufig mit Saanvi zu interagieren oder den Inhalt von Saanvi-Posts zu teilen, und das laufende Video sehr aktuell ist (z. B. ab heute Morgen), besteht möglicherweise eine hohe Wahrscheinlichkeit, dass Juan solche Inhalte mag. Auf der anderen Seite hat sich Juan vielleicht früher mehr mit Videoinhalten als mit Fotos beschäftigt, so dass die ähnliche Vorhersage für Wei’s Cockerspaniel-Foto möglicherweise niedriger ist. In diesem Fall würde unser Ranking-Algorithmus Saanvis laufendes Video höher einstufen als Wei’s Cocker-Spaniel-Foto, da er eine höhere Wahrscheinlichkeit vorhersagt, dass Juan diesen Inhalt mögen wird.
Aber gefällt Juan nur so, wenn er seine Vorlieben ausdrückt? Sicher nicht. Er kann Artikel teilen, die er interessant findet, Videos von seinen Lieblingsspiel-Streamern ansehen oder nachdenkliche Kommentare zu Posts von Freunden hinterlassen. Die Dinge werden mathematisch komplizierter, wenn wir für mehrere Ziele optimieren müssen, die alle zu unserem übergeordneten Ziel beitragen (Schaffung des langfristigsten Werts für die Menschen). Sie können mehrere Werte (Yijtk) haben, z. B. Likes, Kommentare und Freigaben, jeweils für einen anderen Wert von k, dass alle irgendwie zu einem einzigen aggregieren müssen V.ite Wert. Um die Sache noch komplizierter zu machen, müssen für jede Person auf Facebook Tausende von Signalen ausgewertet werden, um festzustellen, was für diese Person am relevantesten ist. Daher wird der Algorithmus in der Praxis sehr komplex.
Wie wählen Sie den übergeordneten Wert für ein Ökosystem von der Größe von Facebook aus? Wir möchten den Menschen, die unsere Dienstleistungen nutzen, einen langfristigen Wert bieten. Wie viel Wert schafft es für Juan, das laufende Video dieses Freundes zu sehen oder einen interessanten Artikel zu lesen? Wir glauben, dass der beste Weg, um zu beurteilen, ob etwas einen langfristigen Wert für jemanden schafft, darin besteht, Metriken auszuwählen, die auf das abgestimmt sind, was die Leute für wichtig halten. Also wir Leute befragen darüber, wie sinnvoll sie eine Interaktion mit ihren Freunden fanden oder ob ein Beitrag ihre Zeit wert ist, um unsere Werte sicherzustellen (UNDijtk) reflektieren Was die Leute sagen, finden sie sinnvoll.
Mehrere Vorhersagemodelle liefern uns mehrere Vorhersagen für Juan: eine Wahrscheinlichkeit, mit der er sich mit Wei’s Cockerspaniel-Bild, Saanvis Laufvideo, dem auf der Seite veröffentlichten Artikel und den Beiträgen der Kochgruppe beschäftigt (z. B. mag oder einen Kommentar dazu hinterlässt). Jedes dieser Modelle wird versuchen, jeden dieser Inhalte für Juan einzustufen. Manchmal sind sich die Modelle nicht einig (z. B. mag Juan Saanvis laufendes Video mit einer höheren Wahrscheinlichkeit als der Page-Artikel, aber er teilt den Artikel möglicherweise eher als Saanvis Video), und die Art und Weise, wie wir jede Vorhersage für Juan berücksichtigen, basiert über die Handlungen, die uns die Leute erzählen (über Umfragen) sind sinnvoller und ihre Zeit wert.
Approximation der idealen Ranking-Funktion in einem skalierbaren Ranking-System
Nachdem wir die Theorie hinter dem Ranking kennen (wie in Juans Newsfeed dargestellt), müssen wir bestimmen, wie ein System für diese Optimierung aufgebaut werden kann. Wir müssen alle verfügbaren Beiträge für mehr als 2 Milliarden Menschen bewerten (durchschnittlich mehr als 1.000 Beiträge pro Benutzer und Tag), was eine Herausforderung darstellt. Und wir müssen dies in Echtzeit tun – also müssen wir wissen, ob ein Artikel viele Likes erhalten hat, auch wenn er erst vor wenigen Minuten veröffentlicht wurde. Wir müssen auch wissen, ob Juan vor einer Minute viele andere Inhalte mochte, damit wir diese Informationen optimal für das Ranking verwenden können.
Unsere Systemarchitektur verwendet eine Web / PHP-Schicht, die den Feed-Aggregator abfragt. Die Rolle des Feed-Aggregators besteht darin, alle relevanten Informationen zu einem Beitrag zu sammeln und alle Funktionen zu analysieren (z. B. wie viele Personen diesen Beitrag zuvor gemocht haben), um den Wert des Beitrags vorherzusagen UNDite an den Benutzer sowie die endgültige Rangliste V.ite durch Aggregation aller Vorhersagen.
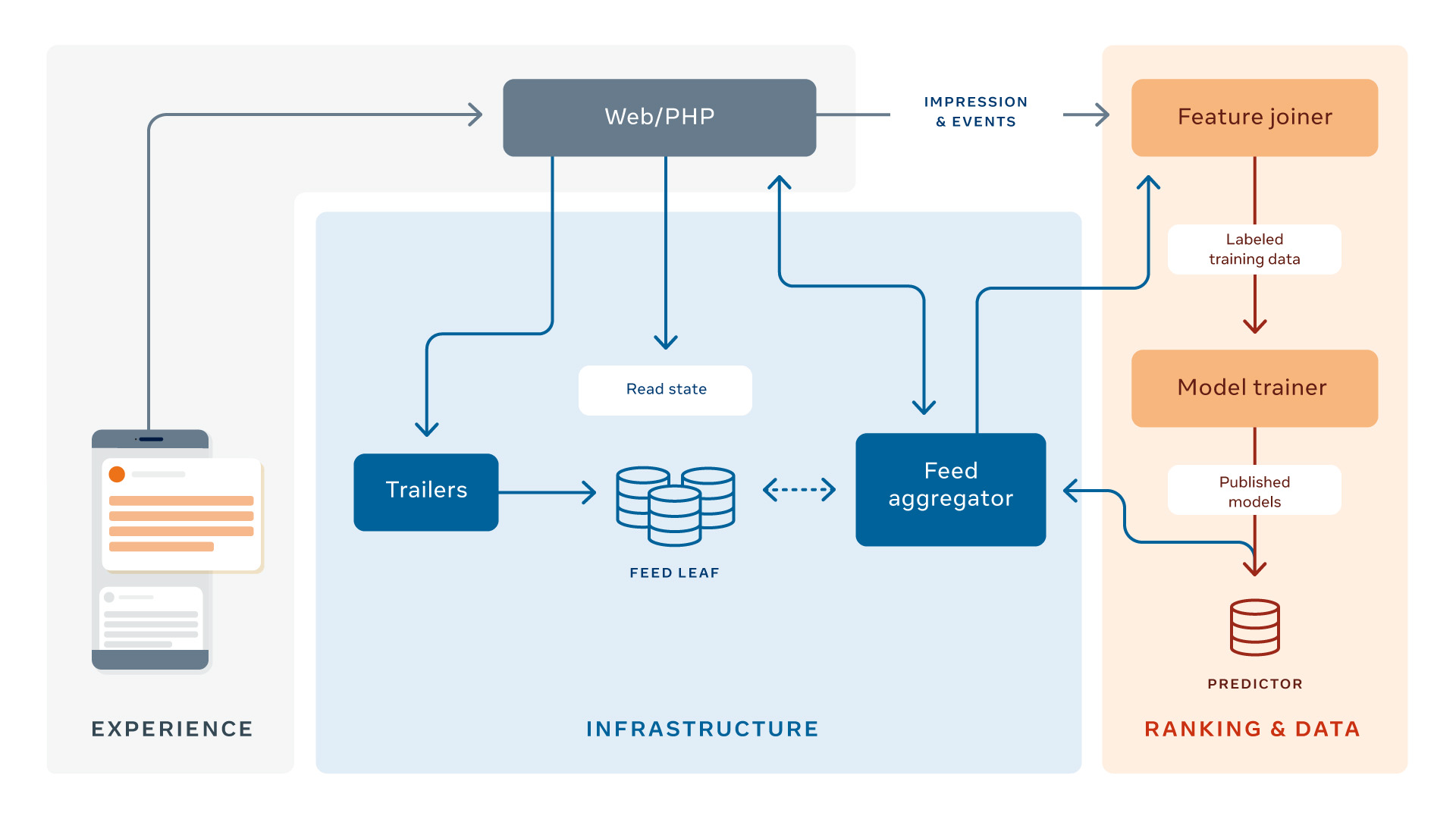 Wenn jemand Facebook öffnet, unabhängig von der Front-End-Oberfläche (z. B. iPhone, Android-Telefon, Webbrowser), sendet die Schnittstelle eine Anfrage an eine Web / PHP-Ebene (Front-End), die dann den Feed-Aggregator abfragt ( Backend-Schicht). Nach dem Akzeptieren einer Anforderung vom Front-End ruft der Feed-Aggregator Aktionen und Objekte zusammen mit einer Objektzusammenfassung aus den Feed-Leaf-Datenbanken ab, damit er die resultierende Liste der bewerteten FeedStories verarbeiten, aggregieren, bewerten und an das Front-End zurückgeben kann zum Rendern.
Wenn jemand Facebook öffnet, unabhängig von der Front-End-Oberfläche (z. B. iPhone, Android-Telefon, Webbrowser), sendet die Schnittstelle eine Anfrage an eine Web / PHP-Ebene (Front-End), die dann den Feed-Aggregator abfragt ( Backend-Schicht). Nach dem Akzeptieren einer Anforderung vom Front-End ruft der Feed-Aggregator Aktionen und Objekte zusammen mit einer Objektzusammenfassung aus den Feed-Leaf-Datenbanken ab, damit er die resultierende Liste der bewerteten FeedStories verarbeiten, aggregieren, bewerten und an das Front-End zurückgeben kann zum Rendern.
Lassen Sie uns nun überprüfen, wie der Aggregator funktioniert:
- Inventar abfragen. Wir müssen zuerst alle Kandidatenposten sammeln, die wir möglicherweise für Juan bewerten können (das Cockerspaniel-Bild, das laufende Video usw.). Der erste Teil ist ziemlich einfach: Das berechtigte Inventar enthält alle nicht gelöschten Beiträge, die ein Freund, eine Gruppe oder eine Seite, mit denen er verbunden ist, mit Juan geteilt hat und die seit seiner letzten Anmeldung erstellt wurden. Aber was ist mit Posts, die vor Juans letztem Login erstellt wurden und die er noch nicht gesehen hat? Vielleicht waren diese qualitativ hochwertiger oder relevanter als die neueren Beiträge, aber er hatte einfach keine Zeit, sie sich anzusehen. Um sicherzustellen, dass auch unsichtbare Beiträge erneut überprüft werden, haben wir eine ungelesene Logik: Neue Beiträge, die Juan noch nicht gesehen hat, die aber in seinen vorherigen Sitzungen für ihn eingestuft wurden, können von ihm erneut angezeigt werden. Wir haben auch eine Action-Bumping-Logik: Wenn Beiträge, die Juan bereits gesehen hat, ein interessantes Gespräch unter seinen Freunden ausgelöst haben, kann Juan diesen Beitrag möglicherweise erneut als Kommentar-Bumping-Beitrag sehen.
- Punktzahl Xit für Juan für jede Vorhersage (Yijt). Nachdem wir nun Juans Inventar haben, bewerten wir jeden Beitrag mit Multitask-Neuronalen Netzen. Es gibt viele, viele Funktionen (xijtc) können wir verwenden, um vorherzusagen UNDiteDazu gehören die Art des Beitrags, Einbettungen (dh Feature-Darstellungen, die von Deep-Learning-Modellen generiert werden) und die Art und Weise, mit der der Betrachter interagiert. Um dies für mehr als 1.000 Beiträge für jede Milliarde Benutzer zu berechnen – alles in Echtzeit – führen wir diese Modelle für alle Kandidatengeschichten parallel auf mehreren Computern aus, die als Prädiktoren bezeichnet werden.
- Berechnen Sie eine einzelne Punktzahl aus vielen Vorhersagen: Vijt. Nachdem wir alle Vorhersagen haben, können wir sie zu einer einzigen Punktzahl kombinieren. Zu diesem Zweck sind mehrere Durchgänge erforderlich, um Rechenleistung zu sparen und Regeln anzuwenden, z. B. die Diversität der Inhaltstypen (dh der Inhaltstyp sollte so variiert werden, dass die Betrachter keine redundanten Inhaltstypen wie mehrere Videos nacheinander sehen). , die von einer anfänglichen Rangfolge abhängen. Erstens werden bestimmte Integritätsprozesse auf jeden Beitrag angewendet. Diese sollen bestimmen, welche Integritätserkennungsmaßnahmen gegebenenfalls auf die für das Ranking ausgewählten Storys angewendet werden müssen. In Pass 0 wird dann ein leichtes Modell ausgeführt, um ungefähr 500 der relevantesten Beiträge für Juan auszuwählen, die für das Ranking in Frage kommen. Dies hilft uns, in späteren Durchgängen weniger Storys mit hohem Rückruf einzustufen, sodass wir leistungsfähigere neuronale Netzwerkmodelle verwenden können. Pass 1 ist der Haupt-Scoring-Pass, bei dem jede Story unabhängig bewertet wird und dann alle ~ 500 teilnahmeberechtigten Beiträge nach Punktzahl sortiert werden. Schließlich haben wir Pass 2, der der kontextbezogene Pass ist. Hier werden Kontextfunktionen wie Regeln für die Diversität von Inhaltstypen hinzugefügt, um die Diversifizierung von Juans Newsfeed zu unterstützen.
- Ein tieferer Blick auf Pass 1: Der größte Teil der Personalisierung erfolgt in Pass 1. Wir möchten die Kombination optimieren UNDijtkin V.ijt. Für einige kann die Punktzahl für Likes höher sein als für Kommentare, da einige Leute sich eher durch Liken als durch Kommentieren ausdrücken möchten. Der Einfachheit und Traktabilität halber bewerten wir unsere Vorhersagen linear zusammen, so dass Vijt = wijt1Yijt1 + wijt2Yijt2 +… + wijtkYijtk. Beachten Sie, dass diese lineare Formulierung einen Vorteil hat: Jede Aktion, die eine Person selten ausführt (z. B. eine ähnliche Vorhersage, die sehr nahe an 0 liegt), erhält automatisch eine minimale Rolle im Ranking, wie Yijtk denn dieses Ereignis ist sehr gering. Um über diese Dimension hinaus zu personalisieren, fahren wir fort Erforschung der Personalisierung anhand von Beobachtungsdaten. Menschen mit höherer Korrelation gewinnen mehr Wert aus diesem bestimmten Ereignis, solange wir diese Methode inkrementell machen und mögliche Störgrößen kontrollieren.
Sobald wir diese Ranglistenschritte abgeschlossen haben, haben wir einen bewerteten Newsfeed für Juan (und alle Leute, die Facebook nutzen) in Echtzeit, der für ihn zum Konsumieren und Genießen bereit ist.
Nachdem Sie die Wissenschaft, die Ranking-Architektur und die Technik hinter News Feed besser verstanden haben, können Sie sehen, wie unser Ranking-Algorithmus dazu beiträgt, eine wertvolle Erfahrung für Menschen in bisher unvorstellbarem Umfang und Geschwindigkeit zu schaffen. Juan profitiert davon, dass er persönlich bedeutungsvollere und interessantere Inhalte sieht, wenn er zu Facebook kommt, ebenso wie Milliarden anderer Menschen. Wir verbessern unser Ranking-System ständig, indem wir unsere Vorhersagemodelle wiederholen, die Personalisierung verbessern und vieles mehr, um Menschen dabei zu helfen, den wertschöpfenden Inhalt zu finden und mit Freunden und Familie in Verbindung zu bleiben.
Comments are closed.